Html filter, protect yourself on the web
Update (March 30 2006) : Downloads of the product held until further notice. HtmlFilter is being strengthened to accomodate today's needs, i.e. filtering of inline text sponsoring ads (as in Google search results) and so on. It will provide greater value and is poised to become a commercial product. No ship date at this time, but that should not be too long a wait.
Xml-based html content filtering
Disclaimer : this tool is free to use and provided as is. Copyright Stéphane Rodriguez 2003-2006.
Introduction
The remainder of this paper describes how to use the html filter product.
The article title came to my mind after I got tired of the nasty little objects in web pages, namely popups, inline JavaScript-ed profilers, etc. In short all those things that do harm, and slow down the web. There was a need to remove all this. The idea of a proxy server that filters out HTML tags according to rules is not really new, and there are lotsa sharewares out there aimed on this. But I wanted something easy to use and configure.
The XML-based HTTP + HTML filtering rules at the basis of this tool open a very large set of opportunities. The remainder of this article shows some of them. Feel free to contribute and add yours. :-)
Filtering out popups of all kinds
Got tired of popups? That's thing of the past. Now with a simple replacement
rule, you just get rid of all those dirty //ndow.open
JavaScript stuff.
Here is the rule:
<filterrule name="//ndow.open">
<enabled>yes</enabled>
<allow contains="tf1.guidetele.com"/>
<content contains="//ndow.open" action="comment"/>
</filterrule>
You may ask for not such an exclusive filtering rule. The <allow
...> filter is designed for that purpose. In the example above, all
//ndow.open JavaScript calls will be filtered out,
except those from this site.
Filtering out other JavaScript code
JavaScript code is either from external files, or inline with the current web page.
External JavaScript code
The first thing we filter out is all the URLs pointing to .js
resources (which is actually external JavaScript code). The second thing is,
because it is possible to download JavaScript code even without pointing to an
explicit .js resource, we filter out the HTTP response against the application/x-javascript mime-type, which is the registered
type for JavaScript code and appears in the Content-Type HTTP field.
Here is the rule :
<filterrule name="javascript">
<enabled>yes</enabled>
<request suffix=".js"/>
<response header="Content-Type" contains="application/x-javascript"/>
</filterrule>
Inline JavaScript code
In order to trash away all code inside <script
language="Javascript"> ... </script> tags:
<content tag="script" action="remove"/>
Filtering ad and flash banners
Ad banners
One of the most prominent ad hosting services in the world is DoubleClick. I
believe their market share is above 60%, which means that almost anywhere you
surf to (except CP, at least these days) you are very likely to face
Doubleclick-served ads. URLs are of the form
http://country.doubleclick.net, where country =
en or fr, or ...With that in hands, it's easy to come
up with a filtering rule:
<filterrule name="ad banners">
<enabled>yes</enabled>
<allow header="Content-Type" contains="image/"/>
<request contains=".doubleclick.net/"/> <!-- doubleclick ads -->
<request contains="/script/admentor/"/> <!-- codeproject ads -->
<request contains="realmedia"> <!-- realmedia ads -->
<request contains="ads"/>
</request>
</filterrule>
This fine rule makes the surfing experience somewhat faster, since a lot of pictures are not downloaded at all. In addition, because banners are not retrieved, they won't either be rendered, thus won't produce the blinking and messy color effects that we all know.
Please note the rule about RealMedia is to filter out another
leading ad hosting service. This rule uses a sub-rule (both must be true).
Flash banners
Flash banners are identified by either URL resources pointing to .swf
files, or by the application/x-shockwave-flash mime-type,
which leads to the rule:
<filterrule name="flash banners">
<enabled>yes</enabled>
<request suffix=".swf"/>
<response header="Content-Type"
contains="application/x-shockwave-flash"/>
</filterrule>
Cookie values and other HTTP request headers
Although the application logic behind the <content...> tag
is naturally aimed to filter out HTML content, to act on what's shown on screen,
I thought there was no particular need to restrict the rather powerful
<content...> tag to HTTP responses.
As a consequence, it is now possible to filter out (replace, comment, remove) values from HTTP request headers. This includes:
- the URL you point to,
- post data (such as login and password data from login forms),
- cookie values (used for user authentication),
and actually any other HTTP headers.
For instance, here is an excerpt of a simple HTTP request:
GET http://stats.hitbox.com/buttons/CH0.gif HTTP/1.0
Accept: */*
: http://comments.f***edcompany.com/
phpcomments/index.php?newsid=95526&sid=1&page=1
Accept-Language: en-us
Proxy-Connection: Keep-Alive
User-Agent: Mozilla/4.0
(compatible; MSIE 6.0; Windows NT 5.0; Microsoft stinks)
Cookie: CTG=1037470757; WSS_GW=V1Arez%rX@C@r@Q@
Host: stats.hitbox.com
Cookie values are stored in the %USER%\Cookies Windows directory and are automatically reflected by your browser based on the target web site domain cookie logic. Replacing the cookie value is a breeze. Here is an example rule :
<filterrule name="automatic logon">
<enabled>yes</enabled>
<content contains="Cookie: CTG=1037470757"
action="replace:Cookie: CTG=5458798"/>
</filterrule>
Using the tool
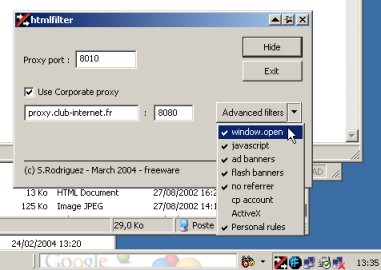
It lives in the systray and has a simple GUI to let you choose the listening port, relaying proxy, and filters.
Configuring the proxy server
Once installed, it starts listening on the default 8010 port. If you are already using this port, change it, that's what the dialog box is for. Of course, you must let the navigator know that you are listening there, so let's open the Windows control panel, then double-click on Internet Options. In the Connections tab, just edit the Proxy Settings, click on Advanced, and type 127.0.0.1 in front of HTTP Proxy address to use server field, and type 8010 in the Port field. Apply. Ok, you're done. You can go back and surf the web as you previously did, without notable changes (at least on surface).
If you are using Netscape or even Opera, just change the proxy settings using a similar procedure. For Netscape, go in the Edit / Preferences, then in Advanced / Proxy, and edit the HTTP Proxy field. The default XML config file provides a rule specifically designed for Mozilla 1.0 to let it work seamlessly (in fact Mozilla 1.0 uses hidden JavaScript HTTP requests, for any reason, and if we don't let them be processed normally, Mozilla just doesn't work!).
Now, depending on whether you have a direct Internet connection, or use the corporate proxy server at your workplace, you must also let the tool know. For a direct Internet connection, just leave the Use corporate proxy unchecked. For a corporate connection, check the box, then fill in the two fields. For instance companyproxy.com (the DNS), and 3128 (the listening port). This information is expected to be known by you (check your LAN Internet settings, check the automatic detection script, ...).
Selecting filters
The list of available filters is known by reading the XML file at startup. In the dialog box, click on Advanced filters to show the list of available filters. Only checked filters are running. If you check or uncheck some filter, the final selection is taken into account internally when you hide the dialog box.
To show the XML file, just click on Show Config. If you edit the XML file, you don't need to restart the tool, just go in the systray, right-click in the menu, and select Reload Config.
HTTP requests can be logged in a file. Right-click in the systray menu, and select Enable logging. Doing so, all HTTP requests are logged to a logfile.log in the directory where the application is running.
XML stuff
Sample config file
<?xml version="1.0" encoding="UTF-8"?>
<htmlfilter>
<enabled>yes</enabled>
<proxyport>8010</proxyport>
<corporateproxy url="proxy.club-internet.fr" port="8080">
<enabled>yes</enabled>
</corporateproxy>
<filterrules>
<filterrule name="//ndow.open">
<enabled>yes</enabled>
<allow contains="tf1.guidetele.com"/>
<content contains="//ndow.open" action="comment"/>
</filterrule>
<filterrule name="javascript">
<enabled>yes</enabled>
<allow contains="http://www.mozilla.org/start/1.0/"/>
<!-- mozilla 1.x rule -->
<request suffix=".js"/>
<response header="Content-Type" contains="application/x-javascript"/>
</filterrule>
<filterrule name="ad banners">
<enabled>yes</enabled>
<allow header="Content-Type" contains="image/"/>
<request contains=".doubleclick.net/"/> <!-- doubleclick ads -->
<request contains="/script/admentor/"/> <!-- codeproject ads -->
<request contains="http://www.codeproject.com/script/ann/ServeImg"/>
<request contains=".googleadservices.com"/> <!-- google ads -->
<request contains=".googlesyndication.com"/>
<allow contains="http://maps.google.com/maps"/>
<allow contains="http://www.flickr.com/photos/"/>
<request contains="http://www.flickr.com/apps/badge/"/> <!-- flickr badge -->
</filterrule>
<filterrule name="flash banners">
<enabled>yes</enabled>
<request suffix=".swf"/>
<response header="Content-Type"
contains="application/x-shockwave-flash"/>
</filterrule>
<filterrule name="onmousemove">
<enabled>yes</enabled>
<content contains="onMouseMove" action="remove">
<content contains="http://www.btinternet.com/~bttlxe/"
action="comment"/>
</content>
</filterrule>
</filterrules>
</htmlfilter>
The grammar (DTD format) :
<!DOCTYPE htmlfilter [
<!ELEMENT htmlfilter (enabled?, proxyport,
corporateproxy, filterrules*)>
<!ELEMENT enabled (#PCDATA)> <!-- yes | no -->
<!ELEMENT proxyport (#PCDATA)> <!-- 8010 -->
<!ELEMENT corporateproxy (enabled?)>
<!ATTLIST corporateproxy url CDATA #REQUIRED> <!-- proxy.isp.com -->
<!ATTLIST corporateproxy port CDATA #REQUIRED> <!-- 8080 -->
<!ELEMENT filterrules (filterrule+)>
<!ELEMENT filterrule (enabled?, allow*, request*, response*, content*)>
<!ATTLIST filterrule name CDATA #required>
<!ELEMENT allow (allow*)>
<!ATTLIST allow header CDATA #IMPLIED>
<!ATTLIST allow prefix CDATA #IMPLIED>
<!ATTLIST allow contains CDATA #IMPLIED>
<!ATTLIST allow suffix CDATA #IMPLIED>
<!ELEMENT request (request*)>
<!ATTLIST request header CDATA #IMPLIED>
<!ATTLIST request prefix CDATA #IMPLIED>
<!ATTLIST request contains CDATA #IMPLIED>
<!ATTLIST request suffix CDATA #IMPLIED>
<!ELEMENT response (response*)>
<!ATTLIST response header CDATA #IMPLIED>
<!ATTLIST response prefix CDATA #IMPLIED>
<!ATTLIST response contains CDATA #IMPLIED>
<!ATTLIST response suffix CDATA #IMPLIED>
<!ELEMENT content (content*)>
<!ATTLIST content tag CDATA #IMPLIED>
<!ATTLIST content contains CDATA #IMPLIED>
<!ATTLIST content action (comment|remove|replace:xxx) #IMPLIED>
]>
A few comments
A nice thing about it is that rules are both serial and hierarchical. They act like OR and AND operators.
Updates history
- Oct 22, 2003 - initial release
- Oct 23, 2003 - added Mozilla rule (to enable Mozilla 1.0)
- Nov 08, 2003 - filtering rule to reject dynamic signatures used in CP forums (such as David Wulff's) ; executable size made 50% smaller, thanks to the use of my own XML framework
- Nov 16 , 2003 -
<content...>tag enabled for all HTTP requests (before it was only used for HTTP responses) ; added the ability to change cookie values ; ability to log HTTP requests - Mar 24, 2003 -
- Navigation recorder : when right-clicking in the systray icon, the Start/Stop recorder and Save Record as... menu options allow to save your navigation clickthroughs. Just select Start recorder, then surf the web. When you are finished, select Stop recorder. You can now save the resulting navigation clickthroughs (xml file-format) with the Save Record as... option. In fact, the recorded clickthrough can be replayed using an external tool, not in the zip package, that simplifies my life on the web. Since the record manages to listen for all HTTP headers including cookies, post data, and pretty much everything else, this allows, after a minor modification, to replay a session-based scenario. Scenarios include the grabbing of your Hotmail inbox new emails without doing anything by hand.
- Instant filtering : this option in the systray menu allows to filter-in/filter-out an url among your navigation history. This usually means a simple and effective way to allow or filter out the content (like external JavaScript, flash banners, ...) from the current website. When choosing this option, a popup dialog opens, and the combo-box gathers the url history. The latest one is preselected. Just choose which one you are interested in, and click ok. This is a convenient way to avoid the hand editing of the xml rules file.
- Referrer rejection rule : this simple rule declared in the xml file allows to automatically filter out the referrer header from your navigation. Referrers are HTTP headers which identify the site you are coming from when you click a link, and this lets the target site build upon that (Google, RSS trackbacks, ...). Rejecting referrers is a great way to enter stealth mode when you surf the web.
- Better multi-threading support, and removal of memory leaks. This version comes with a much improved multi-threading support, removing gliches that users might have experienced in the past.
- February 25, 2006 - update of rules to support Flickr badge filtering (a gadget that some people insert on their home pages) and Google Ads.
Home
Blog