Xml optimization
What is Xml optimization
This is a set of techniques aimed to audit design metadata from any Xml stream. Its purpose is to help Xml producers minimize the side effects of using Xml, such like the size overhead, or the versioning lockdown.For instance, increase in size results in more network bandwidth required to send/retrieve the equivalent Xml content, additionally to the increase in memory space required to store the Xml locally, additionally to the increase in time required for the Xml parser to process the stream.
Xml optimization provides a report showing relevant figures to play with (see screen capture above). With this report in hands, the Xml producers may choose to either use dedicated Xml automation tools to transform Xml streams according to defined rules. Xml producers may find even more appropriate to redesign the whole Xml metadata.
Figures have been calculated and are displayed in the report because they are meaningful for almost any kind of Xml stream, ie each could mean a substantial change in size or design. I have tested over 50 Xml files before coming up with these figures.
Xml optimization is new stuff. Before writing this article, I have browsed through the public internet sites, newsgroups and even quite a bunch of research papers, and I haven't found a single topic addressing it. Amazingly enough, I believe this is not only of interest in the real world - when you know that every company out there in the high-tech industry now uses Xml somehow - this is as crucial as database tuning tools or network tuners. Why isn't this part of leading Xml tools (Xmlspy, Xmetal, Msxml, .NET API) ? I don't know, may be developers are content enough with their use of Xml without really seeing the impact of using Xml instead of binary file formats and standard databases.
What is not Xml optimization
Xml optimization is not about compressing Xml to any proprietary binary format. For that purpose, please don't hesitate to check out xmill (at&t) and xmlppm (sourceforge). Their intent is to make a binary format from Xml by shrinking Xml patterns. And indeed it is very likely to be so because of either of these :- element and attribute names appear many times, thus can be replaced with short tokens
- list of values may contain a lot of duplicated data, by analogy with SQL join records
Xml compression does not steal interest from Xml optimization, since Xml compression is the last thing to use when no smarter code or design principles can be of help - that's brute force in other words -. Xml optimization on the other hand reveals best practices and caveats, thus is bound to help Xml producers learn about their own metadata.
A real world sample
Before going into details, I would like to point a few links to an actual source Xml stream, and the report obtained by applying the tool on it :- Rptcard.xml (usually this opens a new Internet Explorer window)
- Rptcard.stats.html
In the Html report, don't hesitate to click on ? question marks for further info.
The remainder of this article can be broken down into the following sections (reflecting the sections in the Html report) :
Xml optimization : structure in general
General figures about the Xml stream are simple numbers to begin with.Though the meaning of nb lines, nb elements, nb comments is obvious, it is of interest to know what are the effects over an Xml stream with a high nb comments ratio in it. Xml producers usually add comments above, in, or below the actual Xml elements to explain the hierarchy and underlying design. But what they don't know is that in a lot of "content management server (CMS)" software, the Xml is left as is, and sent to clients without removing these unnecessary comments. Resulting in data transport being often 10% larger compared to the size without comments. Of course, in this case, Xml producers are more than encouraged to lift down their Xml code.
nb CDATA sections and nb Process instructions play a simlar role than nb comments.
nb namespaces used is interesting as it reflects whether elements, attributes, and even data itself, use a lot of prefixes, which in turn may significantly increase the size of the Xml stream. For the report to be really useful, figures are often displayed both as absolute values, and as percentages.
Xml optimization : structure in details
Fasten your seatbelt, there are many topics here.→ Structure pattern
This reverse engineers the Xml stream hierarchy by just processing the stream (it nevers read the DTD if any), giving both parent/children relationships, and also datatypes when they are recognized (including float, integers, currencies, dates, urls, and emails).
What for ? reverse engineering the structure pattern is not only a unique feature, it reveals a lot whether the Xml is designed "vertically" (lot of elements), "horizontally" (lot of attributes), or somewhat diagonally. The structure pattern is a preliminary block that must be displayed before proceeding next topics because it simplifies figuring out the design.
→ Flattening the structure pattern
Distinct patterns tells if there is more than one main pattern in the Xml stream. Pattern occurences, Pattern height (amount of lines) and Pattern size (in bytes) show the key characteristics of the main structure pattern. These are figures that are worth mentioning by themselves, but are also preliminary to the next figure.
Now what is flattening patterns ? That's what is obtained by replacing child elements with attributes, where possible. Follows is a sample before and after flattening :
Original Xml :
<person>
<firstname>John</firstname>
<lastname>Lepers</lastname>
</person>
Modified Xml :
<person firstname="John" lastname="Lepers"/>Flattening the patterns makes use of what is known in the W3C Xml norm as empty element tags, ie tags with no slash counterparts, thus reducing the size by significant amounts. Flattening patterns has a lot of interesting effects : 1. for instance, because the hierarchy is flat, the parsing will be faster. 2. it is much easier to do a diff on Xml streams with flatten patterns.
→ Structure depth
The depth we are talking about is the element depth in the hierarchy, ie "1" for the root element, "2" for the direct children, and so on. A measure usually comes with figures such like : the minimum value overall the Xml stream, the maximum value, the average value, and the standard deviation value. A great standard deviation value means that the Xml stream intensively uses indentation, <, > and end tags, which in turn increase the size.
To better reveal the depth, we also list the amount of elements at any given depth.
The depth measure is visually displayed using a bar chart (numerical figures in a list often hide the trend).
For those interested in how the chart is built, using Javascript code, read what follows :
// usage
var tabheight = 120;
var tabdata = new Array(1,15,83,159); // y-axis
var tabtips = new Array("01","02","03","04"); // x-axis
showChart_Max("<p class='m1'>Depth histogram chart</p>",tabheight,"#4488DD",tabdata,tabtips);
// chart library 1.0 - Stephane Rodriguez - free software
function showChart_Max(title, height, color, data, datatips)
{
// don't go too far if no data were passed
if (data.length==0 || data.length!=datatips.length)
return;
// calculate min, max and average
var max = data[0];
var min = data[0];
for (i=0; i<data.length; i++)
{
c = data[i];
if ( max<c )
max = c;
if ( min>c )
min = c;
}
var average = (min+max)/2;
average = Math.floor(100*average)/100;
// output table header
document.writeln ("<table height='"+height+"' cellpadding='0' cellspacing='0' border='0'>");
document.writeln ("<tr><td valign='center'><font size='-1'>max="+max+"</font></td>");
// output data according to max
for (i=0; i<data.length; i++)
{
dataportion = height * data[i] / max; // height of bar
voidportion = height - dataportion; // void between top of the bar and top of the table
document.writeln ("<td height='129' width='15' rowspan='5'> </td>");
document.writeln ("<td width='15' rowspan='5'>");
document.writeln (" <table width='100%' cellpadding='0' cellspacing='0' border='0'>");
document.writeln (" <tr><td height='"+voidportion+"'></td></tr>");
document.writeln (" <tr><td height='"+dataportion+"' bgcolor='"+color+"'></td></tr></table>");
document.writeln ("</td>");
}
document.writeln ("</tr>");
// output min, max and average in first column (rowspan)
document.writeln ("<tr><td> </td></tr>");
document.writeln ("<tr><td><font size='-1'>avg="+average+"</font></td></tr>");
document.writeln ("<tr><td> </td></tr>");
document.writeln ("<tr><td><font size='-1'>min="+min+"</font></td></tr>");
document.writeln ("<tr><td valign='center'></td>");
// output data according to max
for (i=0; i<data.length; i++)
{
j=i+1;
document.writeln ("<td width='15'> </td>");
if (datatips.length==0)
document.writeln ("<td width='15'><font size='-1'>"+j+"</font></td>");
else
document.writeln ("<td width='15'><font size='-1'>"+datatips[i]+"</font></td>");
}
document.writeln ("</tr>");
if (title!="")
document.writeln ("<caption valign='bottom'>"+title+"</caption>");
document.writeln ("</table><br><br>");
}
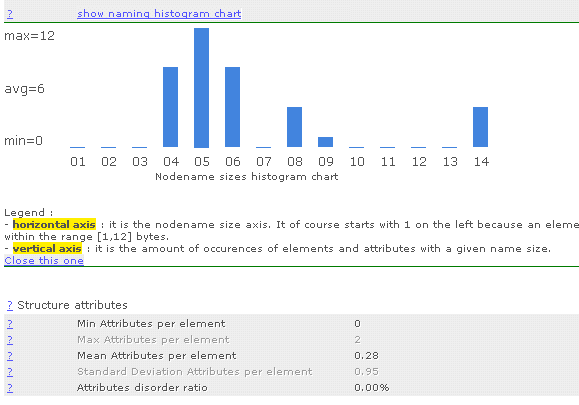
→ Structure node naming strategy
Element and attribute names are usually chosen so they are self-descriptive. While this looks like an advantage, it has an overhead on size just because even in English, keywords enclosing content take statistically a significant space, resulting to a great contribution to the overall stream size. This can be avoided by enforcing a new strategy on naming described below. An element or attribute is any combination of letters and digits. With that in hand, why not make these names as short as possible ? Let us take an example :
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE Bookstore SYSTEM "bookshop.dtd">
<Bookstore>
<!--J&R Booksellers Database-->
<Book Genre="Thriller" In_Stock="Yes">
<Title>The Round Door</Title>
</Book>
</Bookstore>
Let's build a map of name pairs:
Bookstore becomes A
Book becomes B
Genre becomes C
In_Stock becomes D
Title becomes E
So we get the following equivalent Xml document :
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE Bookstore SYSTEM "bookshop_A.dtd">
<A>
<!-- J&R Booksellers Database -->
<B C="Thriller" D="Yes">
<E>The Round Door</E>
</B>
</A>
Similarly with depth, the node naming strategy is also visually reflected using a bar chart, so we see the trend.
The gain resulting from applying the smart node naming strategy to the Xml stream is calculated. That's often 30% or more, which is very very significative.
→ Structure attributes
The Structure attributes indicator reveals how uniform attributes are dispatched within elements. Besides the standard amount of attributes per element (with min, max, mean and standard deviation) is the disorder ratio. The disorder ratio attempts to show if attributes are listed in the same order or not wrt element occurences. That's of course an average, because each element may have any amount of associated attributes. According to the W3C Xml norm, there is no special ordering between attributes, it is simply a good habit to have attributes always following the same order.
→ Structure namespaces
Xml namespaces are declared by using a special attribute of the form xmlns:supplier="http://www.namespaces.com/supplier" and refers to a set of element and attribute names with a dedicated semantic meaning. Element and attributes with namespaces are prefixed by the namespace, for instance supplier:orderID. Namespaces are not required in Xml streams, but they special meanings and may simplify data binding, as long as namespace real meanings are made public and available to everyone. Any number of namespaces can be used, not only one. A namespace must always be declared before it is used. The URL used for the declaration is a fake URL here just for global uniqueness purpose. Below is a sample for the supplier namespace :
<?xml version="1.0" encoding="ISO-8859-1"?>
<Orders xmlns:supplier="http://www.namespaces.com/supplier">
<Order date="AA/45/10" supplier:id="UIYBAB47KDIU75">
<Id>NBZYSJSGSIAUSYGHBXNBJDUIUYE</Id>
</Order>
</Orders>
When namespaces are used, the report shows the ratio of namespaces' use, and the list of namespaces.
Not only using or not namespaces strongly changes the underlying Xml design, they have effect on the node naming strategy, and in turn on the overall size of the Xml stream.
Content itself
Even as the content itself is not part of the Xml metadata, there are many ways to produce size overhead. The simplest of course is to dump data in Xml format from a relational database system, without factorizing duplicate values. It is easy to figure out that there is a lot of gain here.→ Raw content
Content size in element or attribute values exhibit a trend which can be described using minimum size, maximum, average, and standard deviation.
In addition, the ratio of element and attributes with no values is shown. If the ratio is high, easy it is to question whether the design of the metadata is good.
A somewhat odd indicator is the Ratio of multiple part values. Below are two samples of multiple part values for the <book> element :
<book>
The name of this book is so inadequate for a general audience
that it has been decided not to print it.
</book>
...
<book>The Round Door
<year>1999</year>
<price>20$</price>Part II
</book>
→ Content correlation
Content correlation is an in-depth examination of List Of Values that reveals valuables things. The first indicator is related to duplication, or how often the same values appear again and again. And it includes max, average and standard deviation. The second indicator is a ranking, it shows the most seen value in all List Of Values.
→ Content spacing and indentation
Indentation is often used in Xml streams, as they are often designed and read by humans. But indentation produces a signication increase in size. In the report is shown the new size of Xml stream without indentation at all. That's often 30%.
Summary of important measures
Out of the many figures from the HTML reports, several deserve some introductory explanations :
- Flattening patterns : that's the design rule of replacing 1-cardinality elements by attributes. Sounds awful, but a lot of space is gained here.
- Indentation and multiple spaces : beautifying your XML stream is ok, as long as you're dealing with tiny streams. Indented XML streams are simply put twice larger. Just keep this in mind if your server-side component does not scale, and you're wrecking the entire network bandwidth.
- Disorder ratios : that's the kind of measures that help by themselves improve the schema design, and by the way may reduce XML bug fixing.
- Correlation in content : statistically speaking an XML stream has a lot of overhead in size just because content is duplicated rather than factorized.
How to use the tool
Syntax :
single file : betterxml <your file>
betterxml bookshop.xml
betterxml c:\mydir\bookshop.xml
betterxml http://www.mysite.com/xml/bookshop.xml
whole directory : betterxml -d <your directory>
betterxml -d c:\tmp\repository
Technical details
Technically, the tool is based on James Clark's Expat (royalty-free SAX Parser). The executable, which is a report generator on top of a static library can be divided into three parts :
- betterxml.dsp (betterxml.exe), a report generator, contains mostly the HTMLWriter class which is straightforward, and reuses HTML templates stored in the .rc resource file. All strings are localized and ready for a foreign release, if anyone interested. The HTML reports have a built-in chart library (limited to bar charts) allowing to display charts using Javascript.
- SaxAnalyzer.dsp (SaxAnalyzer.lib), an XML extraction library, with the following shade of classes :
- IXmlStats : API to expose measures. Inherits IUnknown.
- AppLogic.cpp : callbacks from the XML parser, calculations of all measures
- Element.cpp : element + attribute API.
- HtmlParser.cpp : general purpose HTML parser, used to extract details that expat does not see.
- XmlFileManager.cpp : manages XML stream reading, including async monikers for URL-based XML streams.
- xmlparser.dsp (xmlparser.lib), the expat library itself.
Both VC6 and VC7 workspaces are provided.Stephane Rodriguez-
September 7, 2002.
Home
Blog